PDF (from Google)
Summary
This paper addresses the problem called federated learning of learning a model from data stored on many mobile devices without sending the data into the cloud. The need for not centralizing data is important both due to privacy concerns and data quantity. This problem is highly valuable in the real world because a lot of data is intrinsically generated on the mobile devices and is privacy sensitive (e.g., personal photos, personal text history).
Difference from Distributed Learning
Though also storing data on a number of distributed devices, federated learning has significant difference and unique challenges compared to distributed learning, which is traditionally studied in the data center context.
- Data stored on federated devices is usually non-IID (highly biased).
- The amount of data is usually severely imbalanced among different devices (heavy user vs. lazy user).
- The # of devices is usually much larger than the # of examples per device.
- Communication to the cloud is the dominating cost and is expensive.
- Device connection to the cloud is intermittent.
- Device user may only be willing to participate in training when they are plugged in.
Federated Learning
The Federated Averaging (FedAvg) Algorithm
The algorithm framework is pretty simple:
- The server (cloud) sends out an initial model to a random fraction C of all clients (mobile devices).
- Each selected client performs a few epochs (E) of SGD on its local model, using mini batch size B, updating its model weights locally.
- Each selected client sends the updated local model to the server.
- The server computes the weighted average of these models.
- The server uses this new central model as the initial model used in the next round.
- Repeat with a different random subset of clients and the updated central model.

Interesting Observations on the Parameters
-
C (fraction of clients involved in each round): Because in Federated Learning we typically deal with a large number of mobile devices, involving all clients in each iteration will be prohibitively expensive. Besides, the authors said they see diminishing return when increasing C.
-
B (local mini batch size) and E (local epochs): These two knobs together controls: (1) how much computation a client performs in one round; (2) how many times the local model gets updated. Remember communication cost dominates in the federated learning settings. Computation on mobile devices is relatively “cheap”. Using extensive experiments, the authors suggest it is usually beneficial to increase the work on clients each round as long as it is not overdone. The authors even suggest to decrease B as long as the hardware’s parallelism is fully exploited, so that the model gets updated more frequently.
Does Model Averaging Actually Work?
The most suspicious part is that, for general non-convex loss functions, simply averaging two models offers no guarantee the averaged model will be any better. In fact, it can be worse than either input models. This problem can even be exacerbated by non-IID data used to train the different input models.
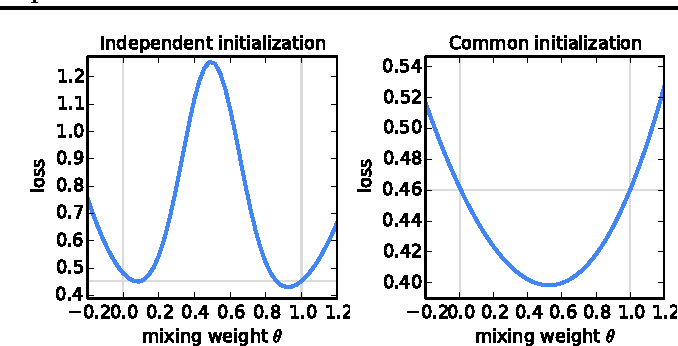
Figure Left below shows an example, where mixing two models with 0.5/0.5 yields higher loss. However, this happens when the two models are initialized independently when they are trained. In Figure Right, the authors empirically showed that, if the two models are initialized the same, even if they are then trained on disjoint data, the averaged model can do better than both.
Going back to the FedAvg algorithm, each round can be seen as a mini instance of Figure Right below, because the server re-initializes all participating clients with the same model. Although, after performing E local epochs, the local models on different clients are likely to diverge, the empirical evidence gives us some relief that averaging them can be beneficial.
Experimental Results
Most of statements made above are drawn from experimental results. The authors did experiments to study the effect of C, E and B on image (MNIST) and NLP data.